Stageproject
Privacy compliance systeem
Afstudeerproject waarin ik een privacy compliance-systeem heb ontwikkeld voor het centraal afhandelen, uitvoeren en controleren van AVG-verzoeken over meerdere gekoppelde systemen.
Afstudeerproject binnen Fotofabriek, onderdeel van Chris Russell, in samenwerking met NHL Stenden.
Introductie
Fotofabriek is onderdeel van Chris Russell, een productiebedrijf in Groningen met meerdere merken en platformen voor print, foto's en gepersonaliseerde producten. Binnen deze platformen worden persoonsgegevens verwerkt, zoals accounts, adressen, ordergegevens en bestanden die klanten uploaden voor hun producten.
Privacyverzoeken werden voorheen grotendeels handmatig uitgevoerd. Een verzoek kwam binnen via de klantenservice, waarna IT, development en soms marketing losse stappen moesten uitvoeren. Omdat persoonsgegevens verspreid stonden over meerdere applicaties, databases en bestandsopslag, was dit proces foutgevoelig en lastig schaalbaar.
Mijn opdracht was om een generieke basis te ontwikkelen waarmee inzage-, portabiliteits- en verwijderverzoeken centraal kunnen worden aangemaakt, uitgevoerd en gecontroleerd. Het moest geen oplossing worden voor een systeem, maar een structuur waarmee meerdere subsystemen later op dezelfde manier kunnen worden aangesloten.
Requirements en onderzoek
Ik ben begonnen met het inventariseren van de stakeholders. Eerst heb ik een interview gehouden met iemand van IT die op dat moment privacyverzoeken uitvoerde. Daarna heb ik interviews gehouden met de key stakeholders: de DPO en het hoofd development.
Uit deze gesprekken is een requirementslijst gekomen. Die lijst is iteratief verbeterd en gevalideerd met de betrokken stakeholders. De globale requirements waren relatief stabiel, omdat ze voor een groot deel voortkwamen uit de AVG en uit het bestaande proces.
Daarnaast heb ik onderzocht hoe de huidige infrastructuur in elkaar zat, welke onderdelen het nieuwe systeem nodig had en waar persoonsgegevens zich in het bestaande landschap bevonden. Daarbij heb ik gekeken hoe gegevens logisch opgehaald, gekoppeld, geexporteerd en verwijderd konden worden. Met die informatie is de requirementslijst aangevuld en is het ontwerpproces gestart.
Stakeholders
IT gaf inzicht in de huidige uitvoering. De DPO gaf inhoudelijke eisen rond AVG en controleerbaarheid. Development gaf technische randvoorwaarden voor beheer en inpassing.
Requirements
De belangrijkste eisen gingen over een centrale interface, het vinden van persoonsgegevens, logging, verificatie, uitbreidbaarheid en ondersteuning van meerdere typen verzoeken.
Infrastructuur
Ik heb onderzocht welke applicaties, databases en opslaglocaties relevant waren en hoe persoonsgegevens door relaties tussen systemen heen gevolgd konden worden.
Ontwerp
In het ontwerp is de oplossing opgesplitst in drie hoofdonderdelen: een backoffice voor gebruikers, een privacy orchestrator voor de centrale verwerking en een subsystem-library om applicaties gestandaardiseerd aan te sluiten.

Backoffice
Interface voor het aanmaken, filteren en volgen van privacyverzoeken. De backoffice laat ook zien welke jobs zijn uitgevoerd en of er fouten zijn opgetreden.
Orchestrator
Centrale laag die verzoeken oppakt, subsystemen aanstuurt, resultaten verzamelt en per stap vastlegt wat er is gebeurd.
Subsystem-library
Herbruikbare .NET-library waarmee een applicatie kan beschrijven welke datasets, persoonsvelden, sleutels en privacyacties beschikbaar zijn.
In het begin zijn vooral de hoofdlijnen ontworpen en gevalideerd met de stakeholders. Daarbij heb ik gewerkt met het 4+1-model en zijn de belangrijkste onderdelen uitgewerkt in UML-diagrammen, zoals de globale structuur, de request-flow en de koppeling tussen orchestrator en subsystemen.
Voor sommige technische onderdelen kostte volledig vooraf uitdenken te veel tijd en was dat inefficient. Vooral bij de privacy index, de id and link collector en de generieke query-opbouw werd pas tijdens de implementatie duidelijk wat praktisch werkte. Daarom is eerst een werkende basis gerealiseerd en is het detailontwerp met de realisatie meegegroeid. Dit is later verder uitgewerkt om het systeem beter te kunnen controleren, verantwoorden en onderhouden.
Realisatie
Bij de realisatie ben ik aan het begin van de flow begonnen en daarna stap voor stap verder gegaan. Eerst werkte het aanmaken van een privacyverzoek in de backoffice. Daarna volgden het oppakken door de orchestrator, het doorsturen naar subsystemen, het verzamelen van data, het maken van plannen en het uitvoeren en verifieren van acties.
Privacy index
De subsystem-library gebruikt reflectie om attributes op Entity Framework entities uit te lezen. Daarmee wordt een index opgebouwd met datasets, persoonsvelden, canonieke sleutels, relaties, bestanden en toegestane acties.
Id and link collector
De collector werkt als een aangepaste BFS. De queue bevat steeds een dataset en een set nieuwe ids. Per relatie zoekt hij verder naar gekoppelde records en bewaart hij via welke link ieder record is gevonden.
Generieke queries
Queries worden dynamisch opgebouwd met expression trees, IQueryableen EF.Property. Daardoor kan dezelfde code verschillende datasets doorzoeken zonder per tabel losse query- of repositorycode te schrijven.
Planvorming
De orchestrator zet gevonden records om naar een uitvoeringsplan. Per dataset wordt bepaald of data moet worden geexporteerd, geanonimiseerd, verwijderd of via een tombstone moet worden afgehandeld.
Tombstone actie
Voor records waarvan relaties moeten blijven bestaan, maakt of hergebruikt het systeem een neutraal record. Afhankelijke verwijzingen worden daarna naar dat record omgezet.
Schema checks
Voor een subsystem wordt gecontroleerd of de privacyconfiguratie klopt. Denk aan ontbrekende tombstone-providers, ongeldige foreign keys, niet bereikbare datasets en fout ingestelde privacyvelden.
De request-flow is job-based opgezet. Nieuwe verzoeken worden door de orchestrator opgepakt, omgezet naar jobs en vervolgens door een worker uitgevoerd. Tijdens de uitvoering blijft zichtbaar welke stap loopt en waar een fout is ontstaan.
Vooral de traversal was een lastig onderdeel. Het systeem mag niet blind alle relaties volgen, omdat je dan te veel data kunt meenemen of in rondjes kunt blijven zoeken. Daarom wordt per requesttype bepaald welke relaties gevolgd mogen worden en houdt de collector bij welke dataset-id combinaties al verwerkt zijn.
De combinatie van index, collector, generieke queries en schema checks maakte het mogelijk om subsystemen op een vaste manier aan te sluiten. Daardoor zit de specifieke kennis over een database vooral in de configuratie, terwijl de orchestrator dezelfde flow kan blijven gebruiken.
DPO-overzicht
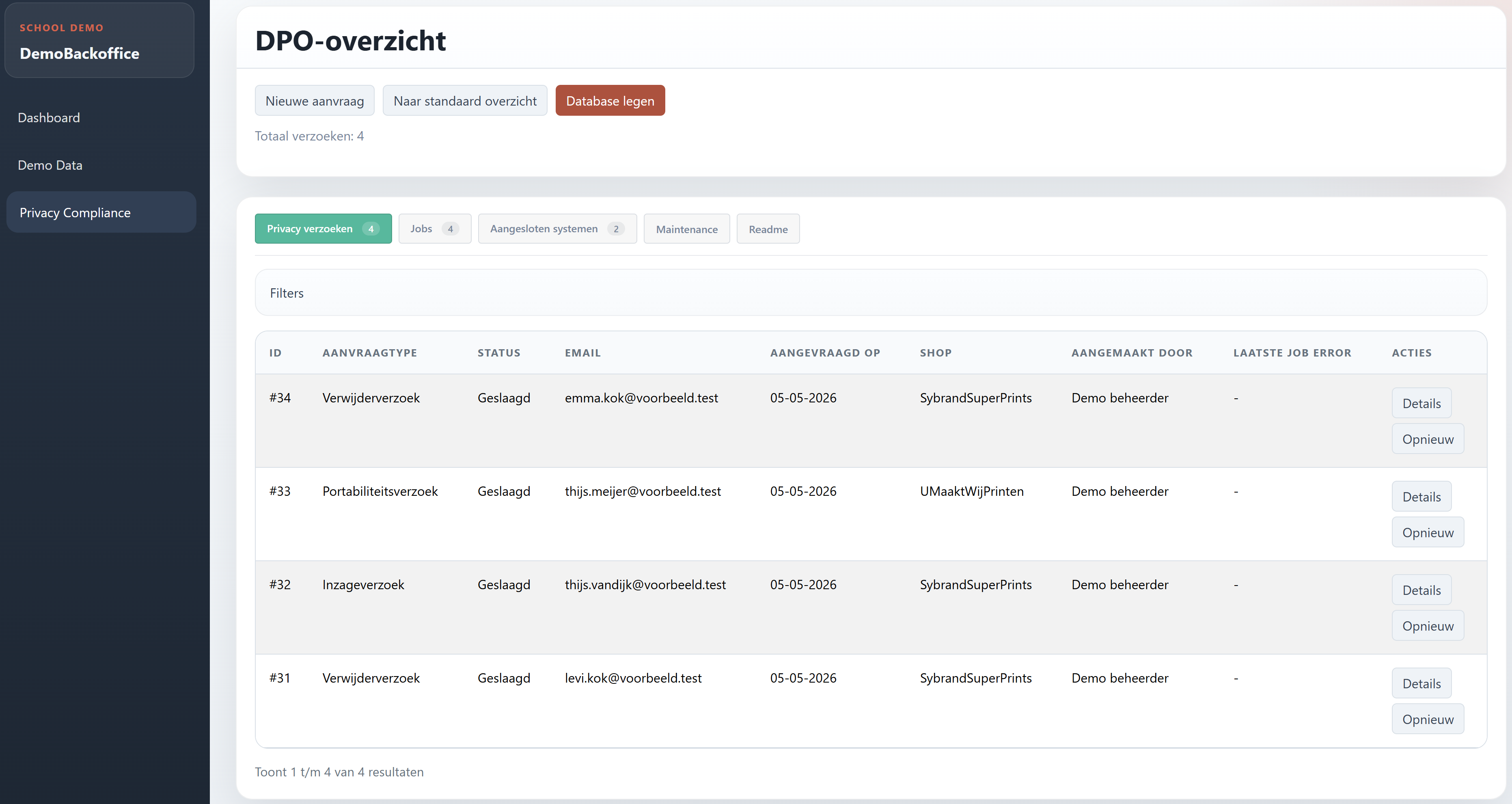
In de backoffice kan een beheerder zien welke verzoeken zijn aangemaakt, welke status ze hebben en of een job opnieuw uitgevoerd moet worden. Dit is belangrijk bij privacyverzoeken, omdat elke stap uitlegbaar en controleerbaar moet blijven.
Testen en validatie
De testaanpak is opgebouwd volgens de testpiramide. Unit tests zijn gebruikt voor losse logica, zoals key-transforms, schema checks, planvorming, query helpers en verificatieregels.
Daarnaast zijn persistentie- en integratietests gebruikt voor onderdelen die afhankelijk zijn van Entity Framework, databasegedrag en de communicatie tussen orchestrator en subsystemen. Voor de volledige flow zijn systeemtests en handmatige controles gebruikt.
De requirements die binnen de technische scope haalbaar waren, zijn uitgevoerd. Een aantal requirements is niet als volledig gerealiseerd afgevinkt, omdat ze verdere verwerking, acceptatie of keuzes buiten de afstudeeropdracht nodig hadden. Die punten zijn daarom niet verwijderd, maar verantwoord als buiten scope of niet realistisch voor deze fase.
Resultaat
Het project heeft een werkende en uitbreidbare basis opgeleverd voor het centraal afhandelen van privacyverzoeken binnen Chris Russell. De basisfunctionaliteit voor aanmaken, uitvoeren, monitoren en verifieren van verzoeken is aanwezig.
De belangrijkste opbrengst is dat het proces technisch is gestandaardiseerd. Nieuwe systemen kunnen via dezelfde subsystem-library worden aangesloten, terwijl de orchestrator dezelfde stappen blijft gebruiken voor verzamelen, plannen, uitvoeren en controleren.
Het systeem vormt daarmee een technische basis voor verdere uitrol. De volledige release en gebruikersacceptatie zijn niet meer binnen mijn stage afgerond, maar de kern van het systeem is technisch gereed voor uitbreiding en verdere ingebruikname.
Wat ik geleerd heb
- Dat een generieke oplossing pas werkt als de verantwoordelijkheden tussen interface, orchestrator en subsystemen duidelijk gescheiden zijn.
- Dat ik ontwerpen simpel moet houden en niet te snel moet kiezen voor veel abstractie of overerving.
- Hoe je persoonsgegevens door relationele modellen kunt volgen zonder de oplossing afhankelijk te maken van een specifiek systeem.
- Hoe belangrijk logging, verificatie en herleidbaarheid zijn bij privacygevoelige processen.
- Dat projectmanagement en stakeholdervalidatie belangrijk zijn om technische keuzes goed te blijven afstemmen op de behoefte van de organisatie.